Principe de fonctionnement des pools
Le pool est un groupe de serveur, c'est a dire que l'on créer un pool : Scani et on met tout nos serveur XCP dedans dont notre XCP-NG-1 que l'on a créer avant, et notre XCP-NG-2, XCP-NG-3 que l'on créer apres.
Cette disposition nous permet surtout d'avoir des fonctionnalité de redondance que l'on appele HA soit Hight Availability qui donne en francais Haute disponibilité.
Parton d'un principe simple, nous avons internet qui rentre avec un routeur. Derriere ce routeur, nous avons 3 machine XCP-NG(1,2,3) et un stockage NFS (Qui est un stockage distant ou dedans on entre nos machine virtuelle).
XCP-NG-1 est notre master et le 2 et 3 nos esclave. Si le premier XCP tombe (Bug,Freeze perte de reseau suite a un port qui crame ou perte d'alimentation) le 2 prendra le relais du master et le 3 restera en esclave jusqu'a ce que le XCP 2 tombe et que le 3 prennent le relais.
Attention toutefois, le HA fonctionne que si nous avons un stockage distant (NFS ou autre)
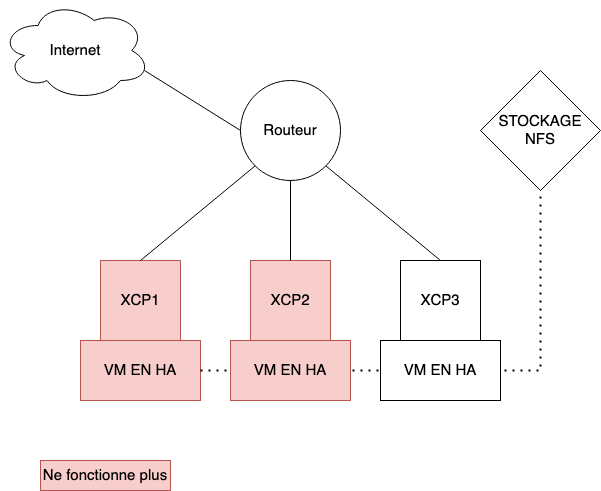
Si il s'avere que une VM est directement dans le stockage hote (sur les disques dur de la machine) la VM ne pourra pas redemarrer sur un autre XCP. Dans le cas ou la VM est bien sur un stockage distant, il faut activer l'option d'autostart pour que la machine ce relance automatiquement quand le XCP-NG-1 plante.
Réseau
Chaque pool a sa configuration réseau spécifique. Tous les hosts d'un pool doivent avoir une typologie d'interfaces communes (par exemple 2 1G + 2 10G dans le même sens). Il semble possible de renommer les interfaces pour les avoir dans le bon ordre mais on n'a pas encore réussi.
Quand on veut modifier le MTU d'une interface réseau dans un pool, il faut passer sur un des host en ligne de commande et faire un
xe network-param-set uuid=0fef8851-03dd-9f1e-9389-94fd712a4ec1 MTU=9000On trouve l'uuid correspondante en faisant un xe network-param-list et en vérifiant l'interface et la dénomination. Il faut ensuite restart la toolstack de chaque host du pool ou rebooter les hosts (il est donc nécessaire d'évacuer les VMs avant)